Det som er 'brukt i livet' er ingen "frossen ulykke"
Jonathan McLatchie 28. april 2026. Oversatt herfra. [kursiv og understreking tilføyd av oversetter]

Francis Crick beskrev den konvensjonelle genetiske koden som en "frossen ulykke", gitt at når kartleggingen mellom kodoner og aminosyrer først er etablert, blir det ekstremt vanskelig å gjøre betydelige endringer uten å ødelegge hvert polypeptid som cellen lager.(1) I de siste tiårene har forskere i økende grad kommet til den erkjennelsen at den genetiske koden ikke er tilfeldig, men svært optimalisert, på flere nivåer.
Ikke bare er selve den genetiske koden finjustert for feilminimering, men det viser seg at settet med aminosyrer som brukes i livet også er svært optimalt - det vil si at utvalget ikke er tilfeldig. I 2011 ble det publisert en artikkel der forfatterne sammenlignet dekningen av standardalfabetet på 20 aminosyrer for "størrelse, ladning og hydrofobisitet med tilsvarende verdier beregnet for et utvalg på 1 million alternative sett (hvert også bestående av 20 medlemmer) trukket tilfeldig fra poolen av 50 plausible prebiotiske kandidater."(2)
Bilde 1: Frossent situasjonsbilde
De fant at
"...standardalfabetet viser bedre dekning (dvs. større bredde og større jevnhet) enn noe tilfeldig sett for hver av størrelsene, ladning og hydrofobisitet, og for alle kombinasjoner av disse. Med andre ord, innenfor grensene av våre antagelser, samsvarer hele settet med 20 genetisk kodede aminosyrer med vårt hypotetiske adaptive kriterium i forhold til alt som tilfeldighetene kunne ha satt sammen fra det som var tilgjengelig prebiotisk."
Jeg skrev om denne artikkelen da den kom ut her.
En nyere artikkel, publisert i 2017 i The FEBS Journal, argumenterte for at settet med aminosyrer som vanligvis brukes i biologien, fundamentalt sett ikke er tilfeldig.(3) Forfatterne hevder at det, sammenlignet med andre sett med aminosyrer i forhold til "komponentatomer, funksjonelle grupper, biosyntetiske kostnader, bruk i en proteinkjerne eller på overflaten, løselighet og stabilitet", er svært gode grunner til at biologien bruker det konvensjonelle settet med aminosyrer og ikke andre. Han bemerker at "Ved å anvende disse kriteriene på de 20 standardaminosyrene, og vurdere noen andre enkle alternativer som ikke brukes, finner vi at det er gode grunner til valg av hver aminosyre. Snarere enn å være en frossen tilfeldighet, ser settet med aminosyrer som er valgt ut til å være nesten ideelt."
 Funksjonelle grupper
Funksjonelle grupper
Doig bemerker at "valget av funksjonelle grupper er ganske begrenset i små molekyler når man bare bruker C, H, O, N eller S." Karbon-nitrogenbindinger, karboksyler, hydroksyler, amider og aminer er stabile kjemiske grupper som kan danne elektrostatiske interaksjoner og hydrogenbindinger. Alternative kjemiske grupper (som estere, anhydrider og nitriler) er for utsatt for hydrolyse i et vandig miljø. Dessuten er aldehyder og ketoner for kjemisk reaktive.
Biosyntetisk kostnad
En annen egenskap som bestemmer hvilke aminosyrer som brukes av cellen, er den energiske kostnaden for biosyntesen deres når det gjelder glukose- og ATP-molekyler: "For eksempel koster Leu bare 1 ATP, men isomeren Ile koster 11. Hvorfor skulle livet derfor noen gang bruke Ile i stedet for Leu, hvis de har de samme egenskapene?" Doig bemerker videre at "Større er ikke nødvendigvis dyrere; Asn og Asp koster mer i ATP enn deres større alternativer Gln og Glu, og store Tyr koster bare to ATP, sammenlignet med 15 for små Cys. Den høye kostnaden for svovelholdige aminosyrer er bemerkelsesverdig."
Bilde 2. Arbeid krever energi-ATP-syntase
Nedgraving og overflate
En tettpakket kjerne i et protein (der det er få tomme rom) maksimerer svake tiltrekninger mellom atomer (van der Waals-interaksjoner: Van der Waals-krefter er svake tiltrekningskrefter mellom atomer og molekyler. De oppstår .. fordi elektronskyene rundt atomene påvirker hverandre.), noe som gjør proteinet mer stabilt. Dermed "er en solid kjerne viktig for å stabilisere proteiner og for å danne en stiv struktur med veldefinerte bindingssteder." Dette betyr at det er viktig å ha ikke-polare sidekjeder for å stabilisere tettpakkede hydrofobe kjerner. På den annen side fremmer polare og ladede aminosyresidekjeder, som er eksponert på en proteinoverflate, løselighet i det vandige miljøet.
Løselighet
Doig bemerker videre at "den minst løselige aminosyren ved pH 7 i vann er Tyr, så en mindre løselig aminosyre enn dette er kanskje ikke akseptabel."
Stabilitet
 Doig bemerker også at "selv med stabile funksjonelle grupper er noen aminosyrer utsatt for uønskede reaksjoner, som syklisering eller acyloverføring, som kan føre til nedbrytning eller racemisering."
Doig bemerker også at "selv med stabile funksjonelle grupper er noen aminosyrer utsatt for uønskede reaksjoner, som syklisering eller acyloverføring, som kan føre til nedbrytning eller racemisering."
Implikasjonene
Doig fortsetter med å vurdere hver av de tjue vanlig brukte aminosyrene, og evaluerer hver enkelts egnethet for liv i forhold til andre aminosyresett. Han konkluderer med at "Det er gode grunner til valget av hver av de 20 aminosyrene og manglende bruk av andre tilsynelatende enkle alternativer. Hvis alt annet mislykkes, kan man ty til tilfeldigheter eller en 'frossen ulykke' som en forklaring." Merkelig nok unnlater han å vurdere en alternativ forklaring, som ser ut til å passe bedre til bevisene, og som vi allerede har uavhengige bevis for - dvs. målrettet utvalg av et intelligent sinn.
Det er viktig å merke seg at disse dataene indikerer at plassen til brukbare aminosyrer er sterkt begrenset. Evolusjonære mekanismer ville derfor måtte utforske et stort kjemisk rom og konvergere mot et svært optimalisert sett. Når den kanoniske genetiske koden er etablert, ville det være ekstremt vanskelig å endre den over tid, siden hver aminosyre ville være knyttet til spesifikke kodoner, tRNAer og aminoacyl-tRNA-syntetaser. å modifisere settet med aminosyrer ville dermed kreve betydelig omkobling. Omfordeling av kodoner og aminosyrer ville påvirke hvert polypeptid laget av cellen og ville forårsake kaos i translasjonen av mange forskjellige proteiner. På den annen side begrenser det å redusere alfabetet av aminosyrer betydelig proteinene som kan lages. Dette ville igjen begrense kjemien og den nødvendige strukturelle presisjonen for primitive systemer for DNA-replikasjon.
Bilde 3. Kun menneskelig design aksepteres
Intelligent design
Intelligente agenter er unikt i stand til målrettet å velge mellom alternativer fra et stort søkerom. Det faktum at settet med tjue aminosyrer som konvensjonelt brukes i livet er ikke-tilfeldig, men faktisk svært optimalisert, er ikke overraskende ut fra hypotesen om at valget deres ble gjort av et intelligent sinn. På den annen side er de veldig overraskende ut fra hypotesen om at det oppsto gjennom ikke-styrte prosesser. I lys av dette overveldende sannsynlighetsforholdet, peker disse funnene på teleologi som den beste forklaringen.
For Referanser, se slutten av originalartikkelen her
Oversettelse, via google oversetter, og bilder ved Asbjørn E. Lund
-----------------
Introduksjon av den bemerkelsesverdige genetiske koden
Av Jonathan McLatchie May 4, 2026. Overrstt herfra
 I en tidligere artikkel -se over, diskuterte jeg implikasjonene av det svært optimaliserte settet med aminosyrer som ofte brukes i biologiske proteiner. Som vi så, gir dette i seg selv et sterkt argument for design. En annen utrolig egenskap ved den genetiske koden er at tildelingene mellom kodoner og aminosyrer er finjustert for å minimere feil som kan oppstå på grunn av mutasjoner. I denne og tre påfølgende artikler vil jeg vurdere flere fasetter av finjustering av den konvensjonelle genetiske koden for minimering av feilpåvirkning. I den siste artikkelen vil vi nøye vurdere i hvilken grad den genetiske koden peker mot design.
I en tidligere artikkel -se over, diskuterte jeg implikasjonene av det svært optimaliserte settet med aminosyrer som ofte brukes i biologiske proteiner. Som vi så, gir dette i seg selv et sterkt argument for design. En annen utrolig egenskap ved den genetiske koden er at tildelingene mellom kodoner og aminosyrer er finjustert for å minimere feil som kan oppstå på grunn av mutasjoner. I denne og tre påfølgende artikler vil jeg vurdere flere fasetter av finjustering av den konvensjonelle genetiske koden for minimering av feilpåvirkning. I den siste artikkelen vil vi nøye vurdere i hvilken grad den genetiske koden peker mot design.
Bilde 4. DNA digitalt registrert
Genetisk koderedundans
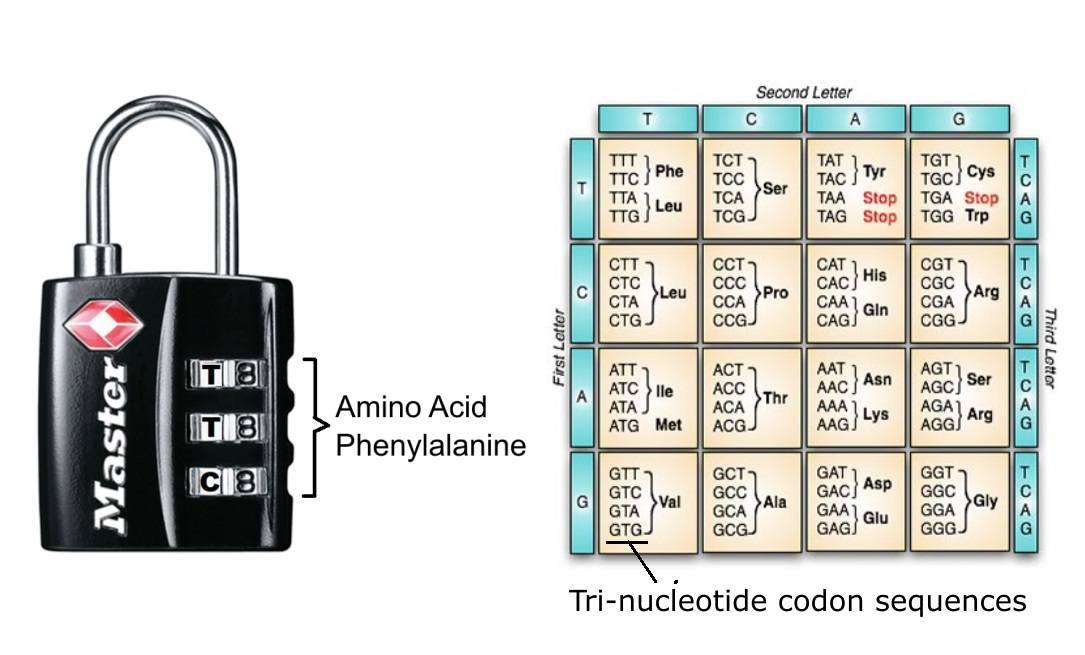
Optimaliseringen av den genetiske koden for feilminimering er muliggjort av kodens redundans. Hva menes med redundans? Det totale antallet mulige RNA-tripletter utgjør 64 forskjellige kodoner. Av disse spesifiserer 61 aminosyrer, mens de resterende tre (UAG, UAA og UGA) fungerer som stoppkodoner, som stopper prosessen med proteinsyntese. Fordi det bare er tjue forskjellige aminosyrer, er noen av kodonene redundante. Dette betyr at flere kodoner kan kode for den samme aminosyren. De cellulære banene og mekanismene som gjør denne 64-til-20-kartleggingen mulig er et under av molekylær logikk. Hvis du trenger en oppfriskning av den bemerkelsesverdige prosessen der mRNA-transkriptet oversettes til proteiner av ribosomet, er her en tre minutter lang animasjon:
Video: mRNA translasjon -lenke (3m:4s)
I alle andre erfaringsområder forbinder vi vanligvis språkkonvensjoner eller kodesystemer med bevisste, overlagte agenter snarere enn ikke-styrte prosesser. Men bevisene for design, som vi skal se, strekker seg langt utover det rene faktum at det genetiske kodesystemet eksisterer.
Minimering av virkningen av punktmutasjoner
 Den genetiske kodens degenerasjon er i stor grad forårsaket av variasjon i den tredje posisjonen, som gjenkjennes av nukleotiden i 5'-enden av antikodonet (den såkalte "wobble"-posisjonen). Wobble-hypotesen sier at nukleotider som er tilstede i denne posisjonen kan gjøre interaksjoner som ikke er tillatt i de andre posisjonene (selv om det fortsatt etterlater noen interaksjoner som ikke er tillatt).
Den genetiske kodens degenerasjon er i stor grad forårsaket av variasjon i den tredje posisjonen, som gjenkjennes av nukleotiden i 5'-enden av antikodonet (den såkalte "wobble"-posisjonen). Wobble-hypotesen sier at nukleotider som er tilstede i denne posisjonen kan gjøre interaksjoner som ikke er tillatt i de andre posisjonene (selv om det fortsatt etterlater noen interaksjoner som ikke er tillatt).
Denne ordningen er langt fra vilkårlig. Faktisk er den genetiske koden som finnes i naturen utsøkt innstilt for å beskytte cellen mot de skadelige effektene av substitusjonsmutasjoner. Systemet er så briljant satt opp at kodoner som bare avviker med én enkelt base, enten spesifiserer den samme aminosyren, eller en aminosyre som er medlem av en beslektet kjemisk gruppe. Med andre ord er strukturen til den genetiske koden satt opp for å redusere effektene av feil som kan oppstå under translasjon (som kan oppstå når et kodon translateres av et nesten komplementært antikodon).
Bilde 5. Språklig koding er resultat av intelligens
For eksempel er aminosyren leucin spesifisert av seks kodoner. En av dem er CUU. Substitusjonsmutasjoner i 3'-posisjonen som endrer en U til en C, A eller G resulterer i endring av kodonene til de som også spesifiserer leucin: henholdsvis CUC, CUA og CUG. På den annen side, hvis C i 5'-posisjonen erstattes med en U, blir kodonet UUU resultatet. Dette kodonet spesifiserer fenylalanin, en aminosyre som har lignende fysiske og kjemiske egenskaper som leucin. Faktumet som trenger å forklares er derfor at kodontildelinger er ordnet på en slik måte at ORF-nedbrytning minimeres. I tillegg spesifiserer de fleste kodoner aminosyrer som har enkle sidekjeder. Dette reduserer tilbøyeligheten til mutasjoner til å produsere kodoner som koder for aminosyresekvenser som er kjemisk forstyrrende.
En artikkel publisert i 2000 fant at den genetiske koden er svært optimalisert, tatt i betraktning to parametere: for det første, den relative sannsynligheten for overganger og transversjoner; og for det andre, den relative effekten av mutasjon.(1) De observerer:
"Når feilverdien til standardkoden sammenlignes med den laveste feilverdien til enhver kode funnet i et omfattende søk i parameterrommet, er resultatene noe mer variable. Estimater basert på PAM-data for det begrensede settet med koder indikerer at den kanoniske koden oppnår mellom 96 % og 100 % optimalisering i forhold til den best mulige kodekonfigurasjonen (fig. 2c). Hvis vår definisjon av biosyntetiske restriksjoner er en god tilnærming til den mulige variasjonen som den kanoniske koden oppsto fra, ser den ut til å være på eller svært nær et globalt optimalt nivå for feilminimering: den beste av alle mulige koder."
En senere artikkel, av Gillis et al., argumenterte for at når de varierende frekvensene av aminosyrer tas i betraktning, ser den genetiske koden ut til å være enda mer optimalisert enn det som tidligere studier hadde antydet.(2) Mens tidligere studier hadde antatt at alle aminosyrer har like stor sannsynlighet for å forekomme i proteiner, gjenspeiler ikke denne antagelsen den virkelige verden, siden aminosyrer varierer betydelig i frekvens - for eksempel forekommer leucin mye oftere enn tryptofan. Forfatterne vektet derfor feil etter hvor ofte en gitt aminosyre forekommer i proteiner. Funnet deres var at hyppige aminosyrer er spesielt godt beskyttet mot mutasjonsfeil. Hyppige aminosyrer er dermed mer beskyttet enn mindre hyppige.
Forfatterne sier:
 "Vi fant at det å ta hensyn til aminosyrefrekvensen reduserer andelen tilfeldige koder som slår den naturlige koden. Denne effekten er spesielt uttalt når mer raffinerte mål på aminosyresubstitusjons-kostnaden brukes enn hydrofobisitet. For å vise dette utviklet vi en ny kostnadsfunksjon ved å evaluere in silico endringen i foldefri energi forårsaket av alle mulige punktmutasjoner i et sett med proteinstrukturer. Med denne funksjonen, som måler proteinstabilitet samtidig som den ikke er relatert til kodens struktur, estimerte vi at rundt to tilfeldige koder i en milliard (10^9) er bedre egnet enn den naturlige koden. Når alternative koder begrenses til de som utveksler biosyntetisk relaterte aminosyrer, virker den genetiske koden enda mer optimal."
"Vi fant at det å ta hensyn til aminosyrefrekvensen reduserer andelen tilfeldige koder som slår den naturlige koden. Denne effekten er spesielt uttalt når mer raffinerte mål på aminosyresubstitusjons-kostnaden brukes enn hydrofobisitet. For å vise dette utviklet vi en ny kostnadsfunksjon ved å evaluere in silico endringen i foldefri energi forårsaket av alle mulige punktmutasjoner i et sett med proteinstrukturer. Med denne funksjonen, som måler proteinstabilitet samtidig som den ikke er relatert til kodens struktur, estimerte vi at rundt to tilfeldige koder i en milliard (10^9) er bedre egnet enn den naturlige koden. Når alternative koder begrenses til de som utveksler biosyntetisk relaterte aminosyrer, virker den genetiske koden enda mer optimal."
Dette optimaliseringsnivået er mye mer ekstremt enn tidligere estimater om at den genetiske kodeoptimaliseringen er én i en million.(3)
Bilde 6. Ooptimaliseringen avgjør ofte resultatet
 En senere artikkel, publisert i BioSystems i 2004, argumenterte for at optimaliseringsnivået til den konvensjonelle koden er enda mer ekstremt.(4) Spesielt observerer de at det finnes en korrelasjon mellom hyppigheten som en aminosyre brukes med og antall kodoner som koder for den. Dessuten har kodoner som bare skiller seg med én base fra stoppkodonene en tendens til å kode for sjeldne aminosyrer som cystein, tryptofan og tyrosin. Disse aminosyrene brukes med lav frekvens og er også ofte kodet med få kodoner. Dette begrenser potensialet for nonsensmutasjoner, som er de mest skadelige mutasjonene (siden de innebærer å bytte ut et vanlig kodon med et stoppkodon, og dermed avkorte proteinet). Forfatterne hevder at når denne optimaliseringsparameteren tas i betraktning, ser koden ut til å være enda mer statistisk eksepsjonell. De setter en nedre grense for den statistiske sjeldenheten til den konvensjonelle genetiske koden til 1 til 2 milliarder.
En senere artikkel, publisert i BioSystems i 2004, argumenterte for at optimaliseringsnivået til den konvensjonelle koden er enda mer ekstremt.(4) Spesielt observerer de at det finnes en korrelasjon mellom hyppigheten som en aminosyre brukes med og antall kodoner som koder for den. Dessuten har kodoner som bare skiller seg med én base fra stoppkodonene en tendens til å kode for sjeldne aminosyrer som cystein, tryptofan og tyrosin. Disse aminosyrene brukes med lav frekvens og er også ofte kodet med få kodoner. Dette begrenser potensialet for nonsensmutasjoner, som er de mest skadelige mutasjonene (siden de innebærer å bytte ut et vanlig kodon med et stoppkodon, og dermed avkorte proteinet). Forfatterne hevder at når denne optimaliseringsparameteren tas i betraktning, ser koden ut til å være enda mer statistisk eksepsjonell. De setter en nedre grense for den statistiske sjeldenheten til den konvensjonelle genetiske koden til 1 til 2 milliarder.
Bilde 7. Kod(on) lås
Bare begynnelsen
Hvis dette var alt som var optimaliseringen av den genetiske koden, ville den være bemerkelsesverdig i seg selv. Det finnes imidlertid flere tilleggsnivåer av finjustering som går utover dette. Den genetiske koden er derfor samtidig optimalisert for flere begrensninger. I min neste artikkel vil vi se hvordan den genetiske koden er optimalisert for å dempe de skadelige effektene av rammeskiftmutasjoner, og for tilstedeværelsen av overlappende kodende sekvenser.
For Referanser, se slutten av Originalartikkelen -her.
Oversettelse, via google oversetter, og bilder ved Asbjørn E. Lund